
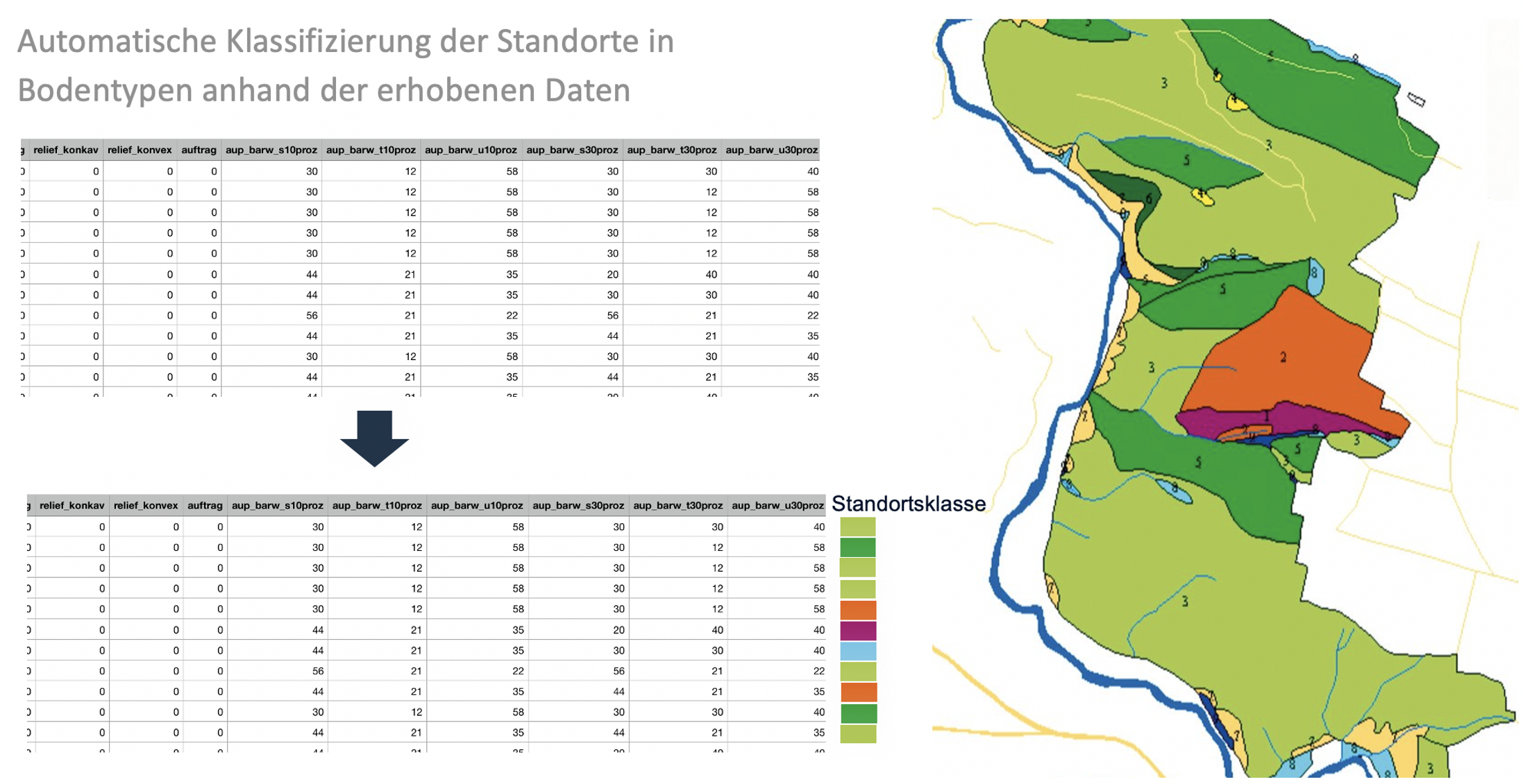

Heute gehen Experten durch den Wald, nehmen circa alle 50 Meter Bohrungen vor und zeichnen die Daten der Bodenproben auf. Anhand dieser Bohrdaten und langjährigen Erfahrungen der Experten wird der Standort in eine von etwa 100 Klassen eingeteilt. Diese Klassifizierung ist Teil der Standortskartierung.
Was ist eine Standortskartierung?
Ein Standort wird in der Forstwirtschaft definiert durch abiotische Umweltfaktoren. Faktoren, an denen Lebewesen nicht erkennbar beteiligt sind, werden als abiotische Umweltfaktoren bezeichnet. Das sind zum Beispiel Luftfeuchtigkeit, Bodenbeschaffenheit, Kalkspiegel oder Niederschlag. Die Aufgabe der forstlichen Standortskartierung ist die Beschreibung, Klassifizierung und flächenhafte Darstellung der Waldstandorte. Man kann sich die Standortskartierung wie eine Art Inventur des Naturraums vorstellen. Sie ist Grundlage für Planungen und Entscheidungen, die den Wald betreffen, wie beispielsweise welche Baumarten gepflanzt werden.
Die forstliche Standortskartierung wird seit 70 Jahren durchgeführt, mittlerweile verfügen ca. 1 Mio. Hektar Wald in Baden-Württemberg über eine digitale Standortskarte. Die Daten der einzelnen Bohrpunkte werden erst seit ca. 10 Jahren digital gespeichert. Die Klassifizierung und die Art zu klassifizieren variieren von Region zu Region. Die manuelle Klassifizierung ist zeitaufwendig und erfordert Fachpersonal mit umfassendem boden- und vegetationskundlichem Wissen. Außerdem wirkt sich der Klimawandel auf die Umweltfaktoren und mögliche Baumarten, die gepflanzt werden können, aus. Das Wissen der Standortskartierung ist wichtig, um auf den Klimawandel reagieren zu können.
Im Rahmen des Proof-of-Concept-Labs wurde mit Herrn Kayser von IDaMa GmbH geprüft, ob unter Verwendung der seit 10 Jahren erhobenen Parameter am Bohrpunkt und Machine-Learning-Verfahren die Vorhersage der in den Karten verwendeten Standortseinheiten reproduziert werden können. Ziel ist es, die bisher regional gültigen Standortseinheiten numerisch vergleichbar zu machen, damit sie unabhängig von der regionalen Erfassung besser in landesweiten Modell verwendet werden können.
Die IDaMa GmbH bietet individuelles Datenmanagement und Auswertung forstlicher Inventuren an. Ein aktuelles Projekt ist die Entwicklung einer Datenbank zur Standortskartierung. Daten aus den Wäldern Baden-Württembergs dieses Projekts dienten als Grundlage für das Proof of Concept.
Bevor Machine-Learning-Verfahren angewendet werden können, müssen die Daten vorbereitet werden. Dieser Teil nimmt in der Praxis circa 80 Prozent der Zeit ein, lediglich 20 Prozent fließen in die Auswahl und Optimierung der Machine-Learning-Verfahren. Auch in diesem Anwendungsfall „Klassifizierung des Standorts“ nahm die Vorverarbeitung der Daten einen erheblichen Zeitanteil in Anspruch.
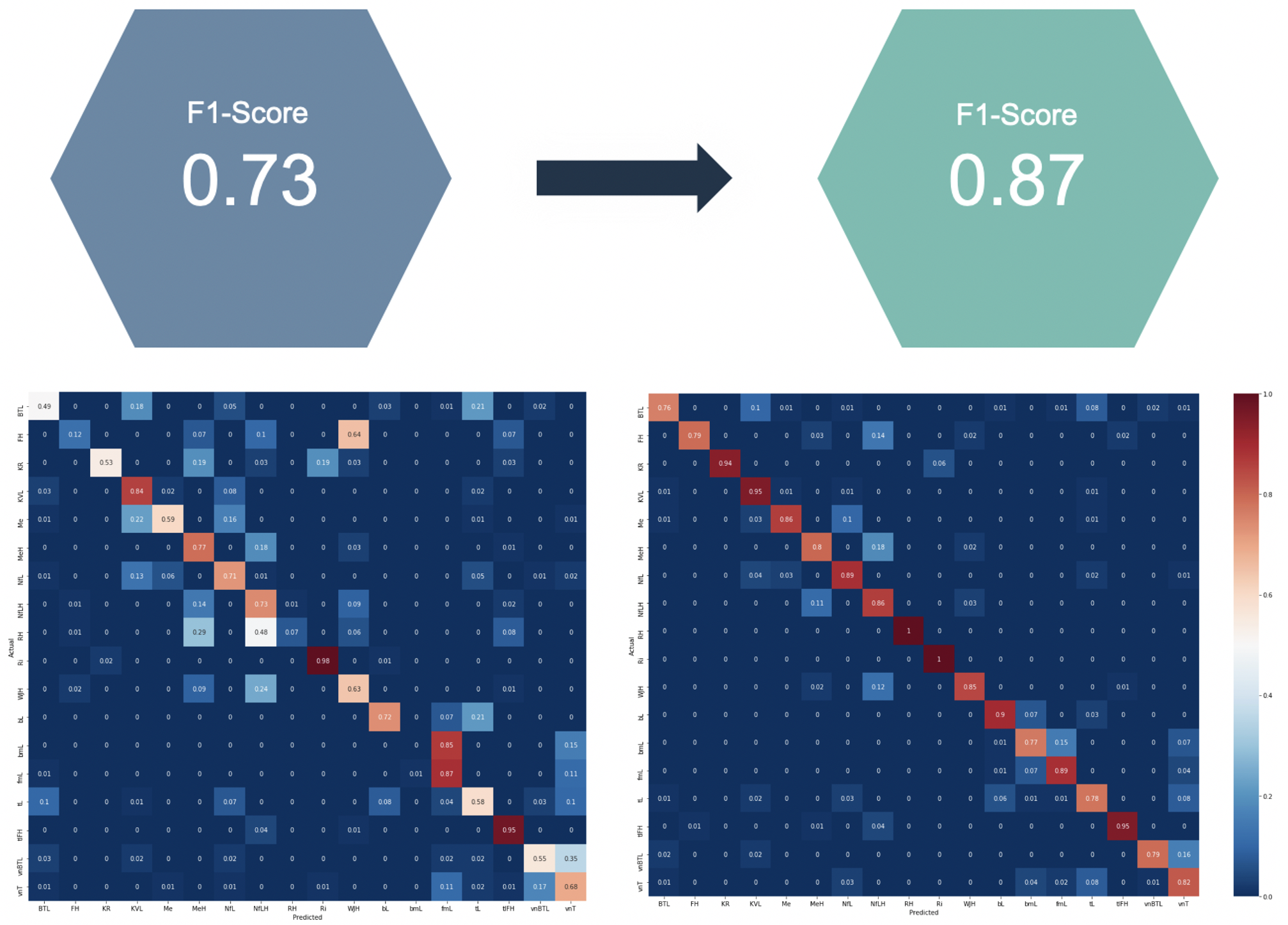
Ein erster Testlauf wurde mit einem Random Forest Classifier (RFC) und einem Neuronalen Netz durchgeführt. Der Random Forest Classifier lag mit einem F1-Score von 0,74 deutlich über dem Neuronalen Netz mit einem F1-Score von 0,63. Die Analyse ergab, dass der Random Forest Classifier besser mit Klassen umgehen kann, die wenig Beispieldatensätze enthalten. Das bereits gute Ergebnis des RFC diente als Basis für weitere Optimierungen.
Das KI-Trainer-Team analysierte gemeinsam mit Herrn Kayser die Ergebnisse des RFC im Detail. Es stellte sich heraus, dass Hangarten mit anderen Hangarten verwechselt wurden. Ebenso bei den Lehmarten. Mit der Fachexpertise von Herrn Kayser und dem technischen Know-how der KI-Trainer konnten weitere Merkmale gefunden werden, die eine Unterscheidung der Hang- und Lehmarten zulassen. In diesem Fall wurden weitere Bohrdaten aus unterschiedlichen Tiefen hinzugefügt. So konnte ein sehr gutes Ergebnis, ein F1-Score von 0,87, erzielt werden.
Die Abbildung 2 zeigt die Confusion Matrix vor und nach der Merkmalsoptimierung. Die Zeilen sind die tatsächlichen Klassen, die Spalten die vorhergesagten Klassen. Hohe Werte werden dunkelrot dargestellt, niedrige dunkelblau. Eine dunkelrote Diagonale von links oben nach rechts unten wäre das Optimum. Die Steigerung mit der Merkmalsoptimierung ist signifikant.
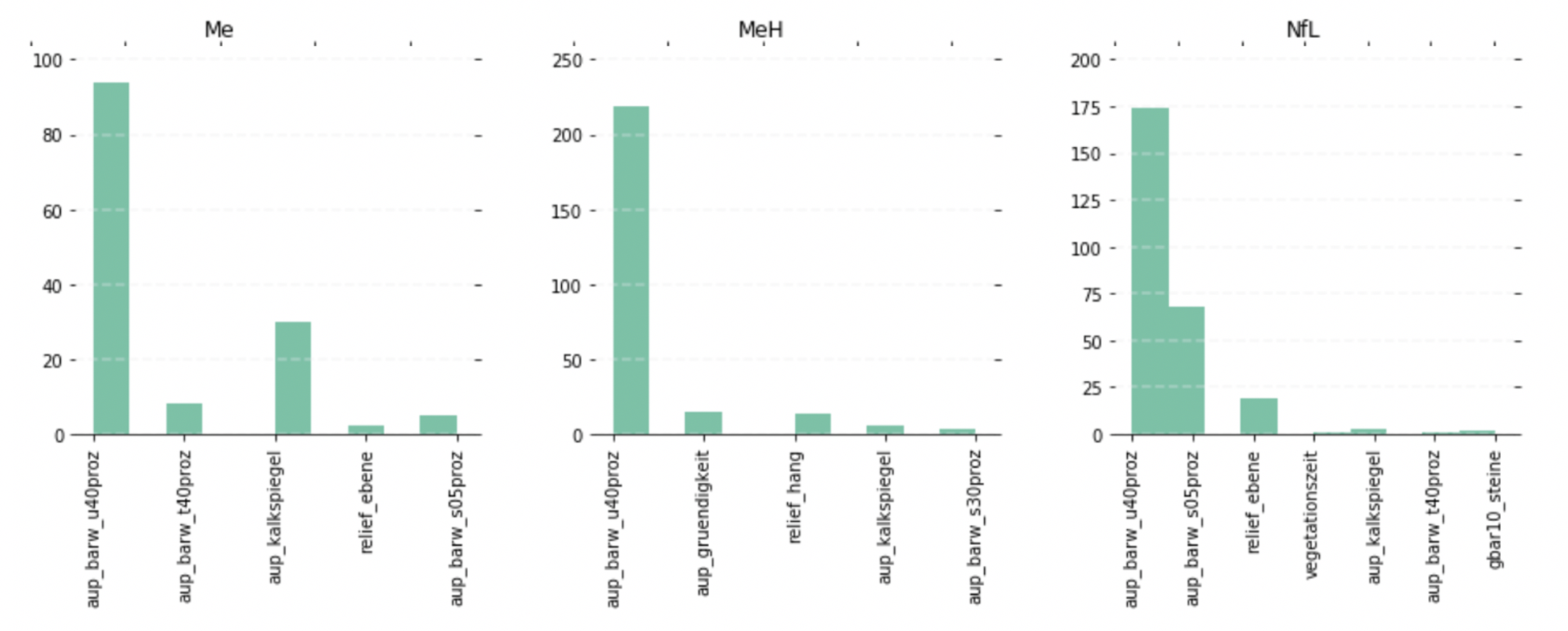
Ein weiterer großer Vorteil von Machine-Learning-Verfahren wie dem Random Forest Classifier gegenüber Neuronalen Netzen ist die Erklärbarkeit. Für Herrn Kayser ist es sehr interessant, welche Merkmale entscheidend für die Klassifikation sind. Die anschließende Analyse des gelernten Models zeigte, dass insbesondere der Kalkspiegel als auch die Messwerte für Ton-, Lehm- und Schluff-Anteile aus 40 cm Tiefe von Bedeutung sind. Aufgrund der interessanten Erkenntnisse wurden die Analyse vertieft und die Bedeutung der Merkmale pro Klasse erhoben und visualisiert.
Die Abbildung 3 zeigt die wichtigsten Merkmale der Klassen Me ( Buchen-Stieleichen-Wald auf mäßig trockenem Mergelboden), MeH (Buchen-Eschen-Wald auf mäßig frischem Mergelhang) und NfL (Buchenwald auf mäßig frischem Nagelfluhlehm).
Die gewonnen Erkenntnisse, welche Merkmale von Bedeutung sind, lässt die Erhebung der Daten effizienter gestalten. Merkmale mit geringer Bedeutung könnten in Zukunft bei der Erhebung vernachlässigt werden.
Das PoC war ein voller Erfolg. Es hat sich gezeigt, dass mit Machine-Learning-Verfahren aus den erhobenen Daten eine Klassifizierung in die Standortseinheiten möglich ist. Außerdem konnten interessante Erkenntnisse über die Merkmale gewonnen werden, die für die weitere konzeptionelle Arbeit und Optimierung der Standortskartierung von Nutzen sind.
Wir bedanken uns bei IDaMa GmbH für die ausgezeichnete Zusammenarbeit und wünschen viel Erfolg bei der Anwendung und Weiterentwicklung der Machine Learning Modelle.
Sie haben eine KI-Anwendungsidee, entsprechende Daten und möchten das kostenfreie Angebot des Proof-of-Concept-Lab wahrnehmen? Jetzt das KI-Trainer Team kontaktieren.
08.06.21
Weitere Informationen
Kontakt


